5-6. Classification Modeling
Spotfire의 Classification Modeling은 보통 통계학에서 이야기하는 분류 모형이 아니라 Logisitic Regression을 말합니다. 물론 분류 모형이라는 큰 의미에서는 Logistic Regression도 하나의 모형이긴 합니다만 Spotfire에서는 그것도 Binomial Logistic Regression만 지원합니다. 이게 무엇을 뜻하는 말이냐면 참과 거짓, 증가와 감소 같이 두 개의 값에 대해서만 적용이 가능합니다. 즉 주어진 데이터를 바탕으로 둘 중 하나를 결정하는 모형이라고 이해하면 될 것 같습니다. 만약 사용자가 3개이상의 값을 가지는 Column을 종속변수로 지정할 경우 분류 중 어떤 것을 참으로 놓고 나머지를 거짓으로 놓을지는 결정해야합니다.
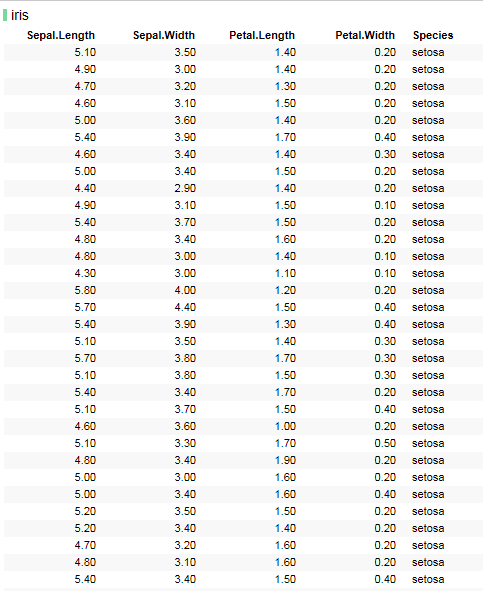
본 예제는 iris 데이터를 활용하여 진행하겠습니다.
해당 데이터를 Spotfire로 가져옵니다.
상단메뉴에서 Tool-Classification Modeling을 실행합니다.
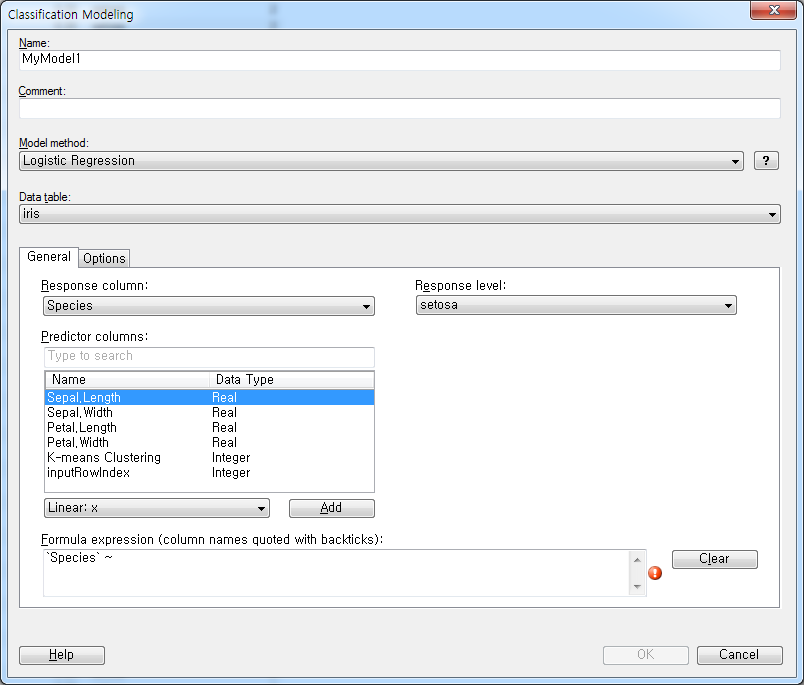
Classification Modeling 각부분에 대한 설명은 다음과 같습니다.
- Name : 모형에 대한 설명입니다. 다수의 모형을 만들 경우 구분할 수 있도록 임의의 이름을 부여합니다.
- Comment : 추가 설명을 달 수 있습니다.
- Model method : Logisitic Regression, Classification Tree 중에서 선택
- Data Table : 대상으로 실행할 Data를 선택
- General
- Response column : 종속변수를 지정, 회귀모형으로 예측하고자하는 대상을 선택
- 지정한 변수가 가지는 값이 3개 이상인 경우 어떤 것은 참으로 할지 우측에 선택 메뉴가 뜹니다. - Predictor columns : 독립변수를 지정할 수 있으며 하단의 함수식을 부여하여 다양한 형태의 회귀분석 모형을 만들 수 있음
- Response column : 종속변수를 지정, 회귀모형으로 예측하고자하는 대상을 선택
- Formula expression : 회귀모형식을 생성, 해당 기능은 R을 기반으로 하기 때문에 이런형태로 구성됨
간단하게 iris의 Species를 종속변수로 넣고 Response Level을 'versicolor'로 지정합니다.
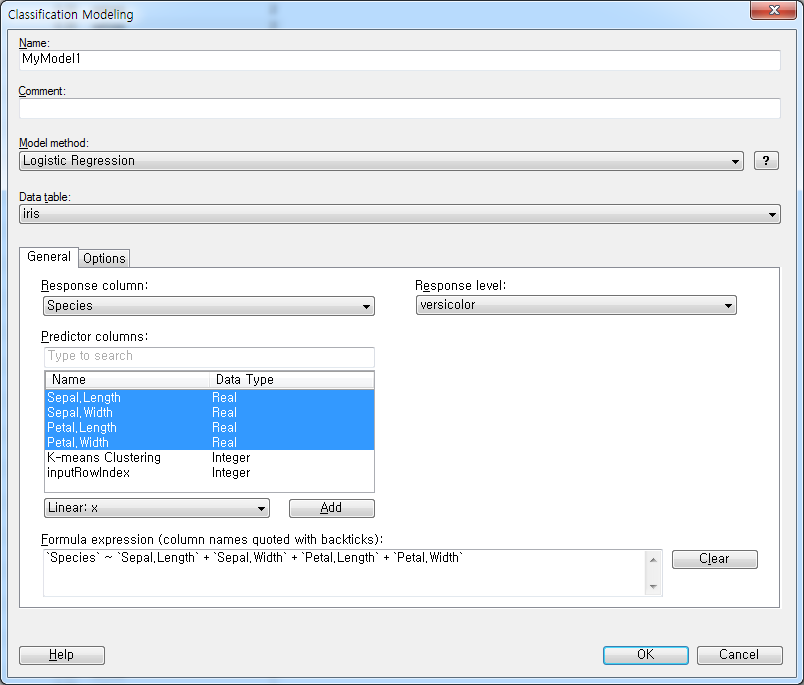
나머지 독립변수를 모두 지정한 후 OK를 눌러 모델링을 시작합니다.

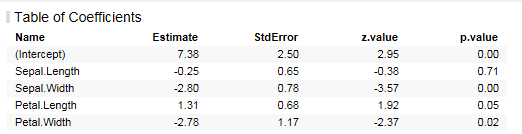
먼저 Table of Coefficients를 보면 Sepal.Length의 p.value가 0.71로 통계적으로 유의하지 않다. Petal. Length도 0.05로 유의하지 않으므로 이 두변수를 제외하고 모형을 다시 수행합니다.


이번에는 Petal.Width가 0.6123으로 통계적으로 유의하지 않으며 AIC값도 기존 155에서 157로 높아졌습니다.
(AIC, Akaike information criterion는 값이 낮을 수록 적합도가 높음을 의미합니다.)


최종적으로 Sepal.Width값을 통해 최종 모형을 만들었습니다. 결과만 놓고 볼때 Sepal.Width가 낮을 수록 Versicolor 종일 가능성이 높은 것으로 알 수 있습니다.
'Data Analysis > Spotfire' 카테고리의 다른 글
| [TIBCO Spotfire] Simple Example : Spotfire & R (0) | 2019.12.01 |
|---|---|
| [TIBCO Spotfire] Spotfire & R (0) | 2019.11.26 |
| [TIBCO Spotfire] Regression Modeling (13) | 2019.11.08 |
| [TIBCO Spotfire]Hierarchical Clustering (0) | 2019.10.30 |
| Line Similarity (0) | 2019.10.16 |




댓글