5-5. Regression Modeling
Spotfire에서 기능 상 Regression 관련 기능이 두 개가 있는데 앞서 설명한 Data Relationship에 있는 Linear Regression과 이번에 소개할 Regression Modeling이 있습니다. 두 기능을 비교해서 말하자면 전자는 단순회귀분석이고 후자는 다중회귀분석입니다. 단순회귀분석은 하나의 종속변수와 하나의 독립변수만을 사용하므로 두 변수간의 선형적인 관계를 분석할 수 있습니다. Regression Modeling은 이와 달리 하나의 종속변수와 다수의 독립변수간의 선형적인 관계를 확인하고 모형을 만들어 예측까지 할 수 있는 기능입니다. Data Relationship의 Linear Regression 보다는 좀더 고급 통계 기능으로 전문적인 통계분석에 가깝습니다.
본 예제는 Boston 주택가격 데이터를 활용하여 Regression Modeling을 진행해보겠습니다. Boston 데이터에 대한 설명은 다음의 글을 참조 부탁드립니다. ([Python] 다중회귀분석(Multiple Regression))
해당 데이터를 Spotfire로 가져옵니다.
다음 상단 메뉴에서 Tool-Regression Modeling을 실행합니다.
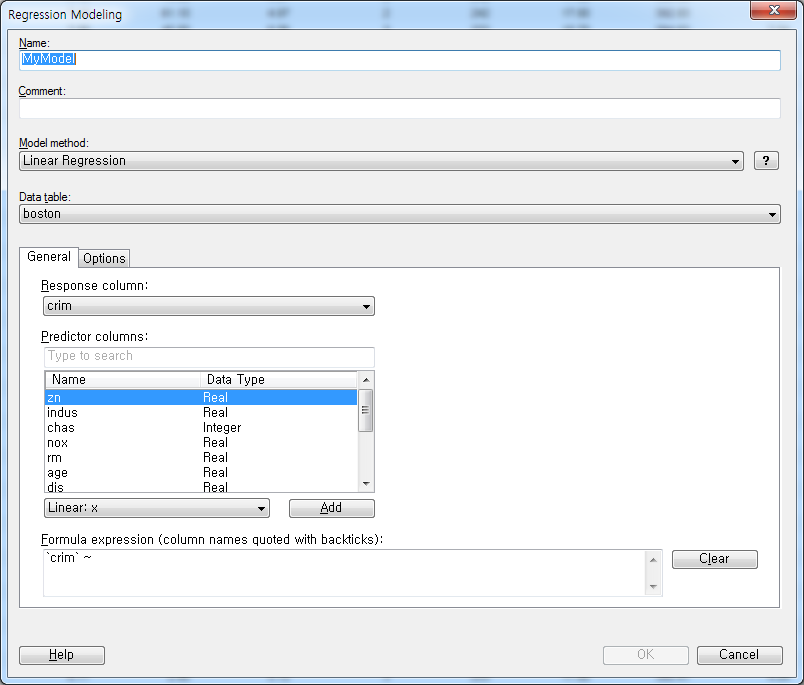
Regression Modeling 각 부분에 대한 설명은 다음과 같습니다.
- Name : 모형에 대한 설명입니다. 다수의 모형을 만들 경우 구분할 수 있도록 임의의 이름을 부여합니다.
- Comment : 추가 설명을 달 수 있습니다.
- Model method : Linear Regression, Regression Tree 중에서 선택
- Data Table : 대상으로 실행할 Data를 선택
- General
- Response column : 종속변수를 지정, 회귀모형으로 예측하고자하는 대상을 선택
- Predictor columns : 독립변수를 지정할 수 있으며 하단의 함수식을 부여하여 다양한 형태의 회귀분석 모형을 만들 수 있음
- Formula expression : 회귀모형식을 생성, 해당 기능은 R을 기반으로 하기 때문에 이런형태로 구성됨
그럼 각 부분에 옵션을 지정해보겠습니다. Name, Comment는 그대로두고 Model method는 Linear Regression, Data Table은 boston을 선택합니다. 예측하고자 하는 대상은 주택가격이므로 medv를 선택하고 나머지 변수는 모두 독립변수로 지정합니다.
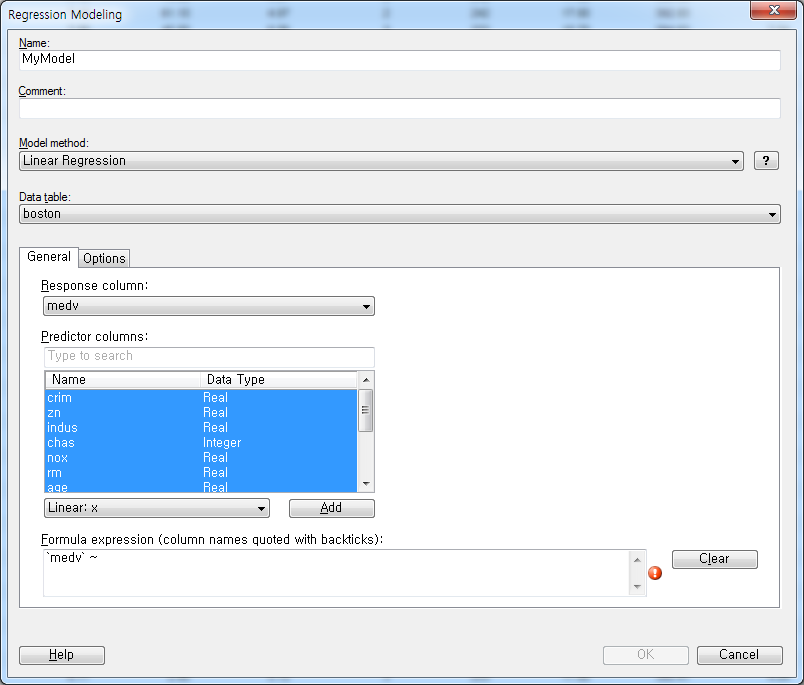
Predictor columns 에서 전체 선택 한후 Add를 클릭합니다.
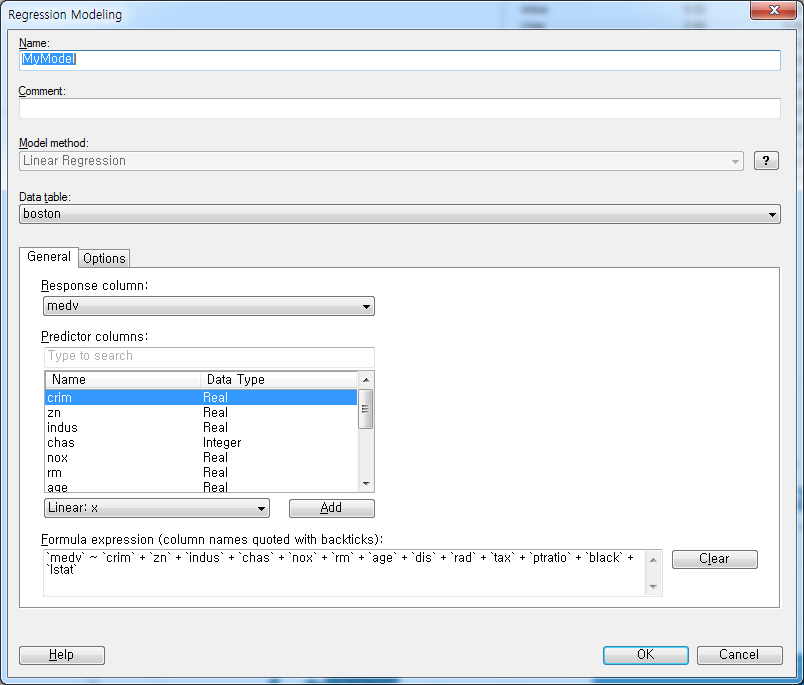
Formula expression에 모형식이 생성된 것을 확인할 수 있습니다. OK를 눌러 Regression Modeling을 실행합니다. 그럼 다음과 같은 결과를 얻을 수 있습니다.
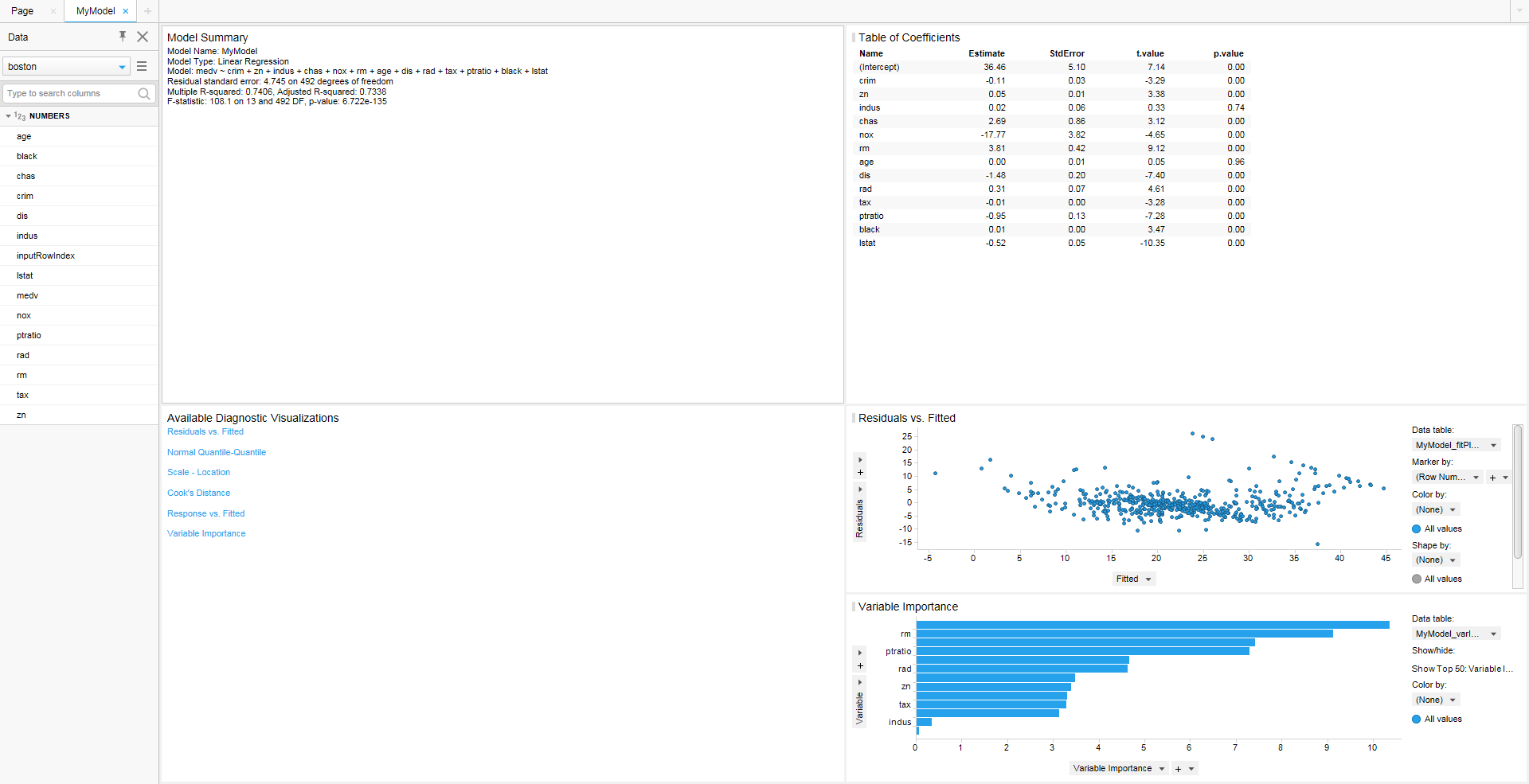
위부분에서 상단의 Model Summary와 Table of Coefficients 만 이해해도 기본적인 Regression Modeling을 활용할 수 있습니다. 각 부분에 대해서 자세히 설명을 해보겠습니다. Model Summary는 말 그대로 모형에 대한 기본적인 정보를 요약한 내용입니다.

주의 깊게 봐야할 부분은 Multiple R-squared, Adjusted R-squared, p-value 입니다.
- p-value는 해당 모형이 통계적으로 유의미한 지를 나타내는 지표로 통상 0.05 이하일 경우 통계적으로 유의미하다고 합니다.
- R-squared는 해당 모형이 주어진 데이터를 얼마나 잘 설명하고 있는지를 나타내는 지표입니다. 통계학자, 적용하는 업에 따라 기준이 천차만별이지만 1에 가까울 수록 모형이 데이터를 잘 설명하고 있는 것입니다. R-squared 값은 변수가 많으면 많을 수록 증가하는 형태를 취하고 있으므로 이에 대한 영향을 줄인 것인 Adjusted R-squared 값입니다.
정리하면 p-value값에 따라 모형이 유의미하고 R-squared 값에 따라 모형이 데이터를 잘 설명하고 있다 판단이 되면 각 독립변수에 대해 검증을 시작합니다. 이에 대한 정보를 Table of Coefficient에서 확인할 수 있습니다.
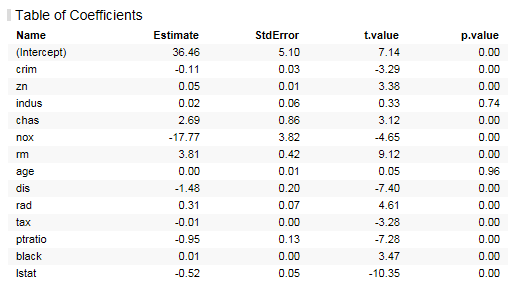
여기서는 각 독립변수에 대한 p-value 값고 Estimate를 확인하면 됩니다. p-value 가 0.05인 경우 통계적으로 유의미한 값이라 할 수 있으며 Estimate는 종속변수에 대한 영향도로 볼 수 있습니다. 위의 결과에서는 indus, age 값이 모두 유의미 하지 않으므로 이를 제외하여 다시 Modeling을 수행합니다.
실행한 모형을 편집하여 재실행해야하는데 Model Summary의 타이틀 부분에 마우스를 가져가면 아래와 같은 아이콘들이 보여집니다.

이중 계산기 모향의 'Edit model'을 클릭합니다. 그럼 아래와 같이 Regression Modeling 창이 다시 뜹니다.
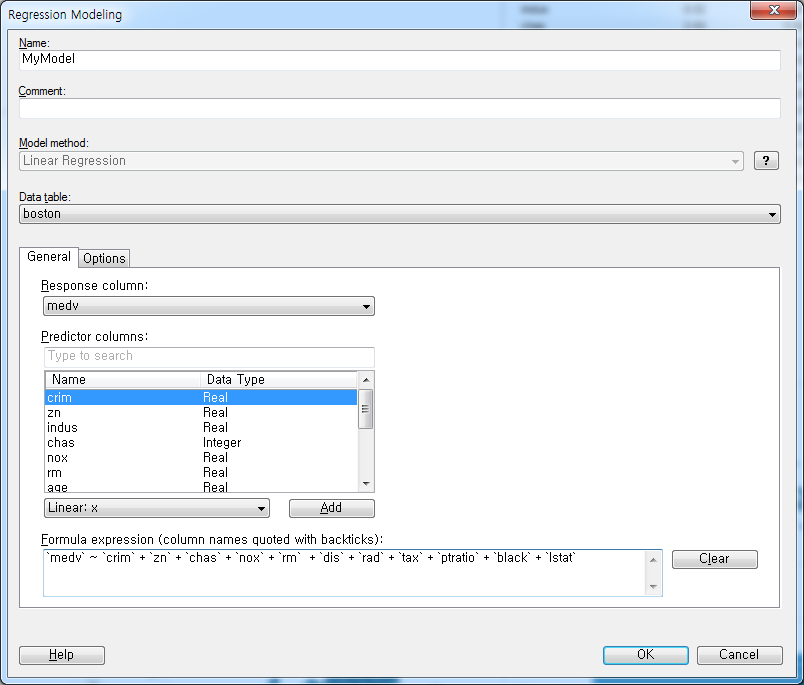
여기서 Formula expression에서 indus와 age 를 삭제한 후 OK를 눌러 실행합니다.
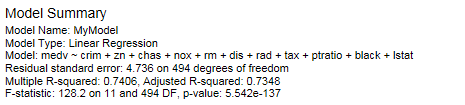
모형에 대한 결과를 다시 확인하면 p-value는 0.05 보다 낮으며 R-squared 값은 0.7 이상으로 데이터를 잘 설명한다고 볼 수 있습니다.
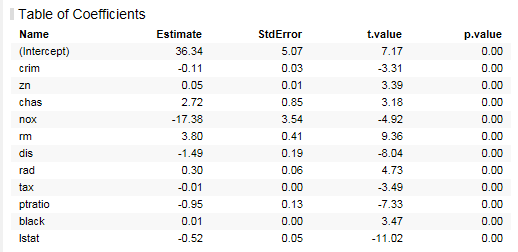
각 독립변수들에 대한 p-value도 모두 0.05 이하이므로 해당 모형을 잘 적합되었다고 할 수 있습니다. Regression Modeling은 상단의 두 정보외에도 추가적인 시각화를 제공하고 있습니다.
- Residuals vs Fitted : 잔차와 적합값간의 관계를 산점도로 보여주고 있습니다. 적당히 잘 흩뿌려져 있으면 좋은 것으로 특정 패턴을 가지면 데이터에 대한 확인이 필요합니다.
- Normal Quantile-Quantile : 회귀분석은 잔차에 대한 정규분포를 가정하고 있으므로 이를 확인할 수 있는 시각화입니다.
- Variable Importance : 투입되는 다수의 독립변수 중 어떤 변수가 중요한 지, 이에 대한 중요도를 나타내는 시각화입니다.
먼저 Normal Quantile-Quantile 차트(Normal QQ-plot)를 보면 굴곡진 형태의 패턴을 가지고 있습니다. 그리고 Residuals vs Fitted 차트를 보면 아래로 굴곡을 지는 추세를 가지면서 우측에 사선형태의 패턴을 가집니다.
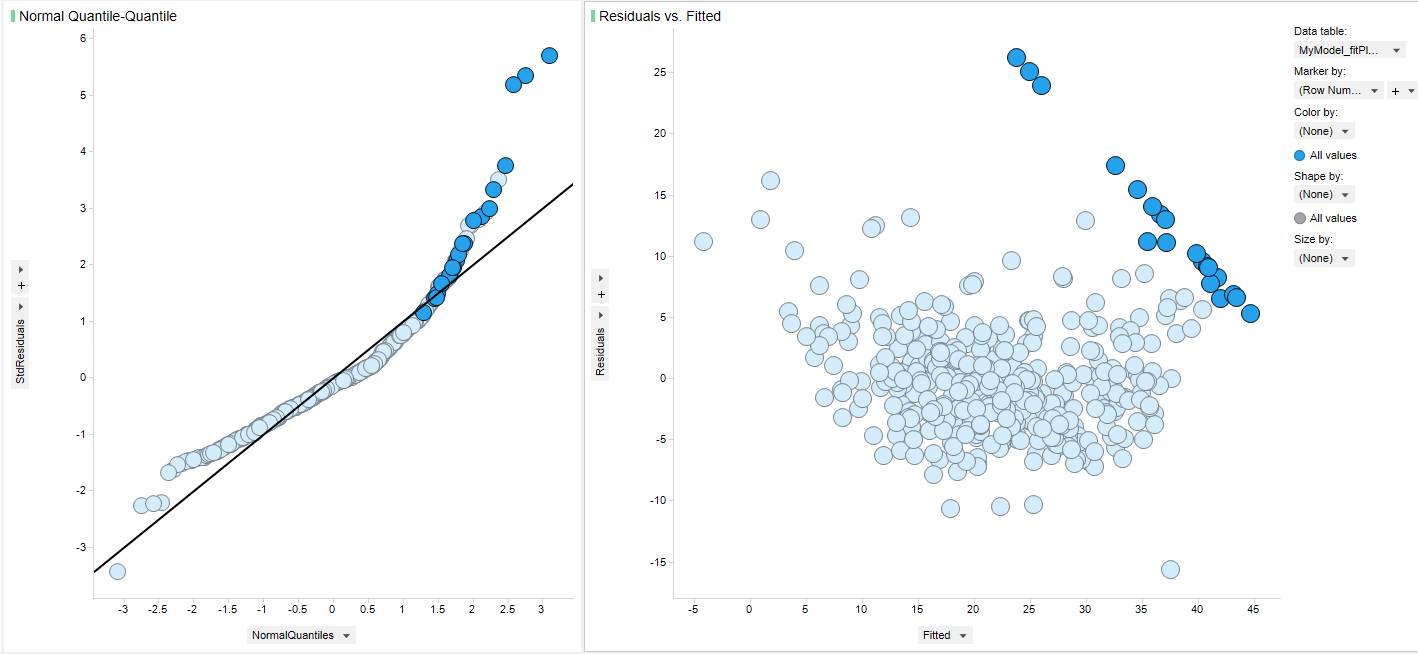
우측 Residuals vs Fitted 에서 사선형태 패턴의 값들을 Marking 해보면 Normal QQ-plot의 상부에 해당하는 것을 확인 할 수 있습니다.
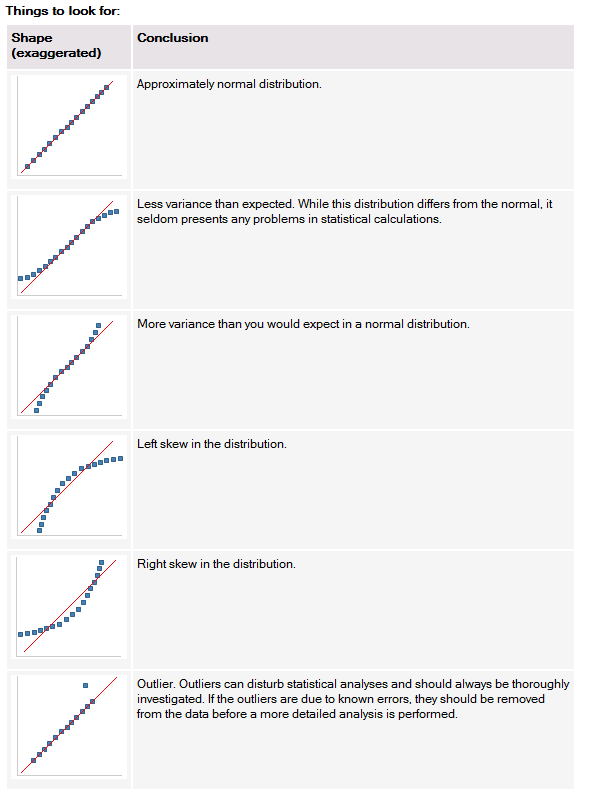
위의 Spotfire 도움말에서 제공하는 이미지를 참조하면 해당 데이터는 정규분포를 따르지 않고 Right skewed 된 분포를 가지며 Outlier가 존재하는 것을 알 수 있습니다. 이 경우 Outlier를 제거하고 정규분포를 따르도록 데이터 변환이 필요한 상황입니다. 다만 이와 같은 형태의 데이터 변환은 통계 지식이 요구되며 고급 Spotfire 기능이 필요하므로 깊게 설명하는 것을 넘어가도록 하겠습니다.
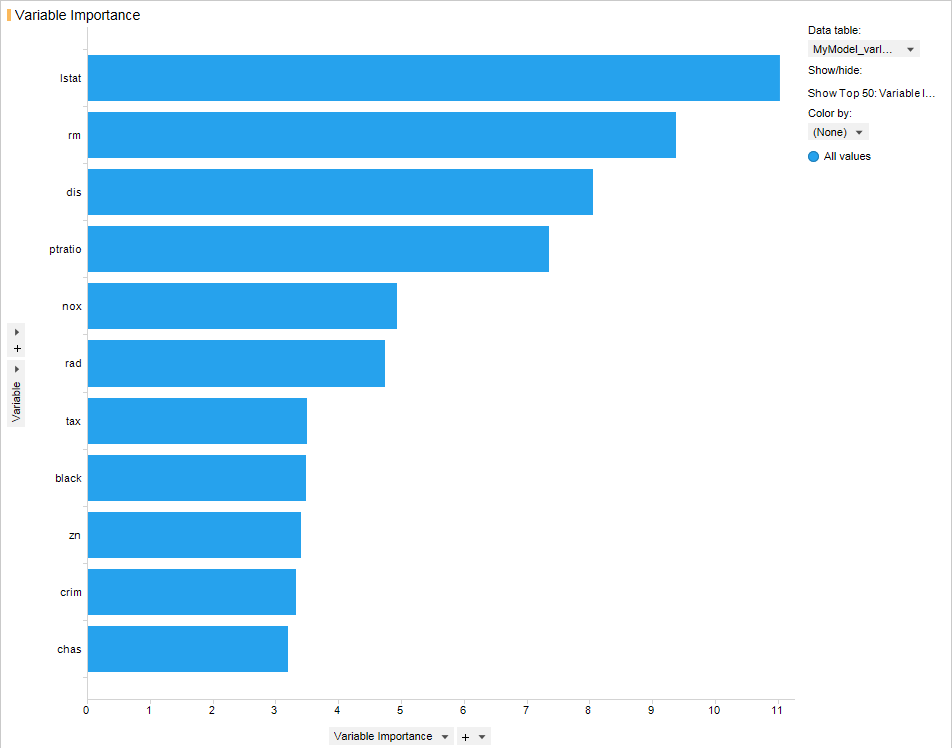
Variable importance에서 보면 lstat 이 가장 중요한 변수로 확인이 됩니다. 단 Estimate 값 기준에서는 nox 값이 가장 영향력이 크며 이 값이 1오를 때 Boston 주택 가격은 -17 떨어질 것으로 예상할 수 있습니다.
이상으로 간단하게 Regression Modeling에 대해서 알아보았습니다.
'Data Analysis > Spotfire' 카테고리의 다른 글
| [TIBCO Spotfire] Spotfire & R (0) | 2019.11.26 |
|---|---|
| [TIBCO Spotfire] Classification Modeling (0) | 2019.11.16 |
| [TIBCO Spotfire]Hierarchical Clustering (0) | 2019.10.30 |
| Line Similarity (0) | 2019.10.16 |
| K-means Clustering (0) | 2019.10.10 |




댓글