5-4. Hierarchical Clustering
Hierarchical Clustering은 K-means Clustering과 마찬가지로 군집분석으로 매우 유명한 통계분석 방법입니다. K-means Clustering의 경우와 비슷하게 데이터 간의 유사성 거리 지수를 활용합니다. K-means Clustering은 각 집단의 평균값을 활용하여 거리를 측정하는데 반해 Hierarchical Clustering는 개별 데이터간 거리를 이용하여 하나씩 짝을 이뤄가며 계층 구조를 만들어 줍니다. 자세한 이론은 넘어가고 Spotfire에서 예제를 진행해보겟습니다. 이번에는 Baseball 데이터를 활용하겠습니다.
해당 데이터를 Spotfire로 가져옵니다.

다음 상단 메뉴에서 Tool - Hierarchical Clustering를 실행합니다.
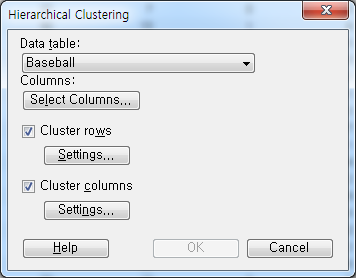
Data Table에서 데이터를 지정하고 Columns에서 입력할 변수를 지정합니다. Cluter rows와 Cluster columns는 각각 행간 군집분석을 할지 열간 군집분석을 할지를 결정하며 그때 사용할 Hierarchical Clustering 군집분석의 세부 알고리즘을 지정합니다. 여기서는 Cluster rows를 활용하여 행간 군집분석을 수행합니다. 먼저 Columns를 클릭합니다.

간단하게 AtBat 부터 Hit by Pitch 까지 지정합니다.
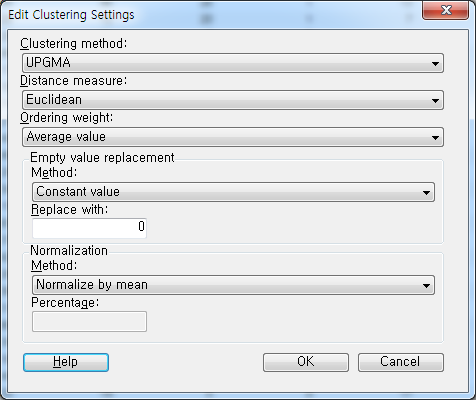
다음으로 Cluster rows에서 Setting을 클릭합니다. 그러면 추가 옵션을 설정할 수 있는데 제일 처음 것이 군집화 방법, 두번째 것이 거리 측정 방법입니다. 기본상태로 두고 OK를 클릭합니다. Hierarchical Clustering를 실행하면 다음과 같은 시각화 차트를 얻을 수 있습니다.

해당 시각화 차트는 Heat Map으로 좌측에 간단한 인터페이가 붙어있는 시각화 차트입니다. 그리고 좌측에 계층 구조의 형태의 그림이 그려져있는데 이를 이용해서 군집이 어떻게 나뉠지를 보고 실제 몇개의 군집으로 나눌지를 결정할 수 있습니다. 붉은 점선은 마우스로 클릭 후 드래그 하여 움직일 수 있으며 붉은 점선에 따라서 군집갯수를 결정합니다.

위의 이미지를 보시면 붉은 점선에 따라서 #의 숫자가 달라지는것을 확인 할 수 있습니다. 좌측부터 군집 갯수가 4개, 5개, 8개로 나뉘어집니다. 이와같이 계층 구조를 가지는 트리에서 몇개의 군집을 나눌지 사용자가 직접 선택이 가능하며 어떤 구조에서 데이터가 분류되는지 시각적으로 확인이 가능합니다.

나누어진 군집은 위와같이 새로운 Column으로 생성이 되며 이를 활용하여 추가적인 시각화가 가능합니다. 산점도를 그린 후 아래와 같이 Trellis에 해당 칼럼을 부여합니다.

그 후 Hierarchical Clustering 결과에서 붉은 점선을 움직이면 그에 따라 산점도에 군집이 적용되어 출력이 됩니다.

위와 같은 구성으로 군집 갯수를 결정한 후 각 군집별 특성이나 군집간 비교를 쉽게 진행할 수 있습니다.
'Data Analysis > Spotfire' 카테고리의 다른 글
| [TIBCO Spotfire] Classification Modeling (0) | 2019.11.16 |
|---|---|
| [TIBCO Spotfire] Regression Modeling (13) | 2019.11.08 |
| Line Similarity (0) | 2019.10.16 |
| K-means Clustering (0) | 2019.10.10 |
| [TIBCO Spotfire] Data Relationship - Chi-square (0) | 2019.09.25 |




댓글