[R] 주식 DATA 수집/분석 - NAVER 주식 Data 가져오기 -2
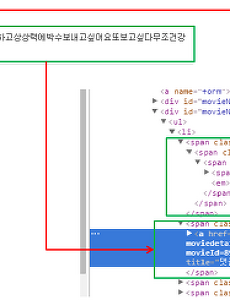
이번에는 다량의 주식 데이터를 가져와서 Database에 저장해보겠습니다. 먼저 Database를 간단하게 만들어 봅니다. CREATE TABLE test..DD_STOCK_PRC ( CODEVARCHAR(6) NOT NULL ,DTDATE NOT NULL ,CLOSE_PRCINT NOT NULL ,DIFF_RTREAL NOT NULL ,OPEN_PRCINT NOT NULL ,HIGH_PRCINT NOT NULL ,LOW_PRCINT NOT NULL ,VOLUME_QTYINT NOT NULL ,PRIMARY KEY CLUSTERED (CODE, DT) ) 네이버 주식 데이터의 순서를 참조하여 주식코드, 일자, 종가, 전일비, 시가, 고가, 저가, 거래량 순으로 저장하는 구조입니다. 다음으로 저번과는 달리..
2020. 5. 17.
[R] 주식 DATA 수집/분석 - NAVER 주식 Data 가져오기 -2
이번에는 다량의 주식 데이터를 가져와서 Database에 저장해보겠습니다. 먼저 Database를 간단하게 만들어 봅니다. CREATE TABLE test..DD_STOCK_PRC ( CODEVARCHAR(6) NOT NULL ,DTDATE NOT NULL ,CLOSE_PRCINT NOT NULL ,DIFF_RTREAL NOT NULL ,OPEN_PRCINT NOT NULL ,HIGH_PRCINT NOT NULL ,LOW_PRCINT NOT NULL ,VOLUME_QTYINT NOT NULL ,PRIMARY KEY CLUSTERED (CODE, DT) ) 네이버 주식 데이터의 순서를 참조하여 주식코드, 일자, 종가, 전일비, 시가, 고가, 저가, 거래량 순으로 저장하는 구조입니다. 다음으로 저번과는 달리..
2020. 5. 17.