
이전에 주식종목 코드 하나에 대해서 주식 정보를 가져온 후 Database에 저장을 했습니다. 이번에는 여러 종목 코드를 가져와서 저장할 수 있도록 준비를 해보려고 합니다. 먼저 주식 종목 코드를 가져와야하는데 아래의 한국거래소에서 이미지에 표기 된 순서대로 이동을 하면 사장회사 검색화면을 띄울 수 있습니다.
한국거래소
www.krx.co.kr

상장회사검색 화면 우측에 보면 데이터를 다운로드 받을 수 있도록 excel, csv 형식으로 지원하고 있습니다.
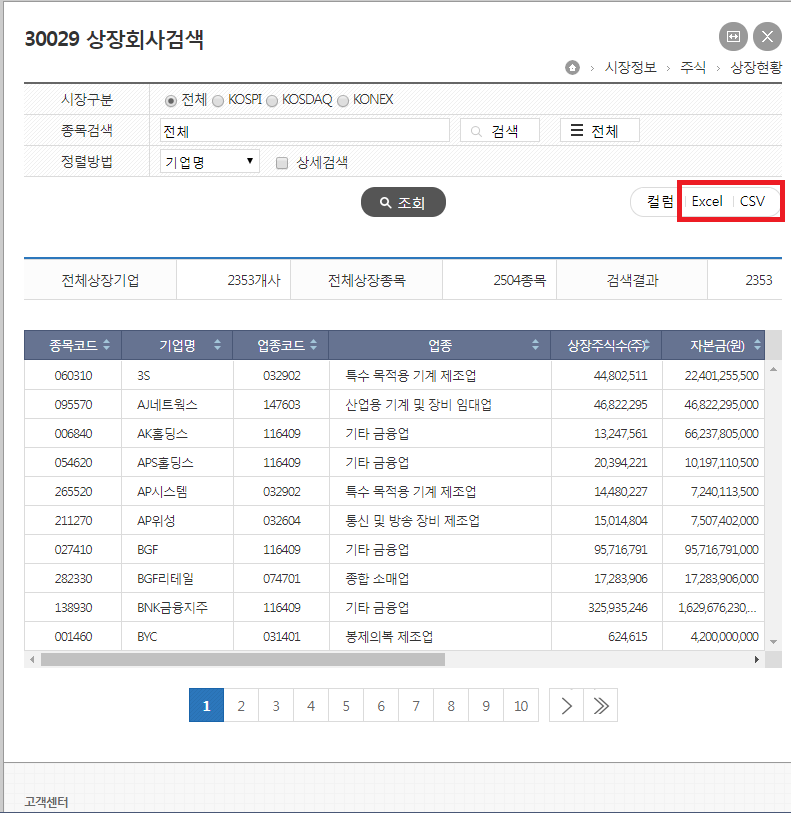
일단 csv 파일로 해서 "c:/temp/"에 저장했습니다. 파일을 열어보면 종목코드, 기업명 외에 상장 주식수, 자본금등의 정보를 제공합니다. 문제는 구분자로 사용되어야할 ","(콤마) 가 숫자내에도 같이 들어있어서 난감합니다.

저 숫자 안의 (콤마) 때문에 보통 R에서 많이 쓰는 read.csv가 제대로 동작하지 않는데 이 경우에는 readr 이라는 패키지를 사용합니다. 그전에 먼저 불러오는 데이터를 저장할 data table을 생성합니다.
CREATE TABLE test..STOCK_CODE (
STOCK_CODE VARCHAR(6) NOT NULL
, STOCK_NM VARCHAR(50) NOT NULL
, INDS_CODE VARCHAR(6) NOT NULL
, INDS_NM VARCHAR(100) NOT NULL
, PRIMARY KEY CLUSTERED (STOCK_CODE)
)
그 다음 다운로드 받은 read.csv 파일을 readr을 이용하여 불러옵니다.
library(readr)
codes <- read_csv('c:/temp/data.csv')
codes <- as.data.frame(codes[,2:5], stringsAsFactors = F)
colnames(codes) <- c('STOCK_CODE','STOCK_NM', 'INDS_CODE', 'INDS_NM')
head(codes)
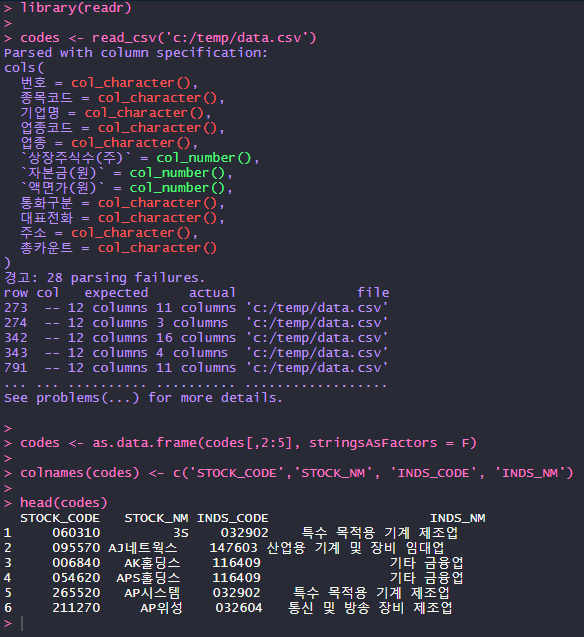
readr은 위의 데이터와 같은 경우 알아서 매우 똑똑하게 데이터를 가져옵니다. 그 결과 종목 코드와 기업명 두개 칼럼을 가진 codes 가 생성됩니다. 이것을 위에서 만든 datatable 에 넣습니다.
library(RODBC)
#MSSQL 연결
msconn <- odbcConnect("mssql", uid='*****', pwd='*******')
insertIntoDb <- function(conn, data, tableName) {
data.colnames <- colnames(data)
dataTable <- sqlQuery(msconn, paste0('select top 1 * from ', tableName))
dataTable.Colnames <- colnames(dataTable)
if (sum(data.colnames %in% dataTable.Colnames) == length(dataTable.Colnames)) {
for (i in 1:nrow(data)) {
query <- paste0("insert into ", tableName)
query <- paste0(query , " (", paste(data.colnames, collapse = ","), ") VALUES ('")
query <- paste0(query , paste(data[i,], collapse = "','" ), "')")
sqlQuery(conn, query)
}
}
}
insertIntoDb(msconn, codes, 'test..STOCK_CODE')
그러면 가져온 데이터들이 모두 database에 저장됩니다. 이제 저장된 주식 코드를 활용해서 매일 주식정보를 가져오도록 해봅시다. 먼저 들어간 주식코드 정보를 가져옵니다.
codes <- data.frame(sqlQuery(msconn, 'select * from test..STOCK_CODE'), stringsAsFactors = F)
head(codes)

코드를 지정하면 현재 저장된 데이터와 비교하여 최종 저장된 데이터 이후 데이터만 저장하도록 다음의 함수를 생성했습니다.
getStockList <- function(code, dbconn) {
# code 확인
if(nchar(code) != 6) {
cat(code, 'is not STOCK CODE.\n')
return(NULL)
}
# 지정된 주식코드 기준 마지막 데이터를 확인
lastStock <- sqlQuery(dbconn, paste0('select top 1 DT from test..DD_STOCK_PRC WHERE CODE = ',code,' ORDER BY DT DESC') )
# 해당 주식코드의 데이터가 없으면 약 300일치데이터를 가져오고 아니면 현재 기준 최종일과의 차이만큼 데이터를 가져옴
if (nrow(lastStock) == 0) {
diff.days <- 300;
} else {
# 아니면 현재 기준 최종일과의 차이만큼 데이터를 가져옴
diff.days <- abs(as.integer(lastStock$DT - as.Date(Sys.Date())))
}
# 현재 기준과 최종 데이터일자간의 차이가 있으면
if (diff.days >= 1) {
pageNum <- diff.days %/% 10 + 1 # 페이지 수 계산
stockDt <- lapply(1:pageNum, function(x) getStock(code, x))
stockDt <- do.call('rbind', stockDt)
stockDt.subset <- subset(stockDt, DT > lastStock$DT) # 최종일자 이후 데이터만 선택
insertIntoDb(dbconn, stockDt.subset, 'test..DD_STOCK_PRC') # 데이터 저장
}
}
그러면 앞의 저장했던 주식 코드들에 대해서 이 함수를 반복 수행하여 전체 주식정보를 가져와서 저장합니다.
# 다수의 코드에 대해서 진행할 거라 소량씩 조금씩..
for (i in 1:500) {
cat(i,'---', codes[i,]$STOCK_CODE, '---', codes[i,]$STOCK_NM, '\n')
code <- codes[i,]$STOCK_CODE
getStockList(code, msconn)
}

다음번에는 해당 데이터를 활용해서 데이터 분석을 해보려 합니다.
'Data Analysis > R' 카테고리의 다른 글
| [R] 주식 DATA 수집/분석 - NAVER 주식 Data 가져오기 -2 (0) | 2020.05.17 |
|---|---|
| [R] NAVER 주식 DATA 가져오기-1 (1) | 2020.05.07 |
| [R] Apply 함수를 알아보자 (0) | 2020.04.21 |
| [R] DAUM 영화 평점을 가져와서 분석하기 - 2 (0) | 2016.02.23 |
| [R] Daum 영화 평점을 가져와서 분석하기 - 1 (2) | 2016.02.23 |



댓글