
오랜만에 해보는 R 공부? 입니다. 이번에 해볼 것은 R을 이용해서 NAVER 금융의 주식 데이터를 가져와보려합니다. 해당 주제는 여러분들이 공부해서 이미 많은 포스팅이 있지만 한번 독학으로 쭉 진행해보려합니다.
1) NAVER 금융 페이지
예시로 카카오 주식(035720)을 검색해서 페이지를 띄워보겠습니다. '시세'탭을 클릭해서 보면 아래와 같은 화면을 얻을 수 있습니다.


1-1) 개요 부분
현재가, 고가, 저가,거래량등 개요부분이 있고 아래 쪽으로는 주요시세, 시간별 시세, 일별 시세가 있습니다. 시간별 시세, 일별 시세는 페이지 구조로 구성되어 장기간의 데이터를 얻을 수 있는 구조로 되어있네요. 먼저 개요부분 html을 뜯어봅니다. 카카오 시세가 206,000원으로 되어있는데 이부분을 구조를 보면 아래와 같습니다.

재미있는 건 개발자 모드에서 켜서 보면 저렇게 보입니다만 소스보기를 하면 저사이에 숨겨진 코드가 더 있음을 알 수 있습니다. (개발자 모드에서 볼 수 있는 방법이 있을 수 있겠지만 일단은 제가 잘 몰라서..)
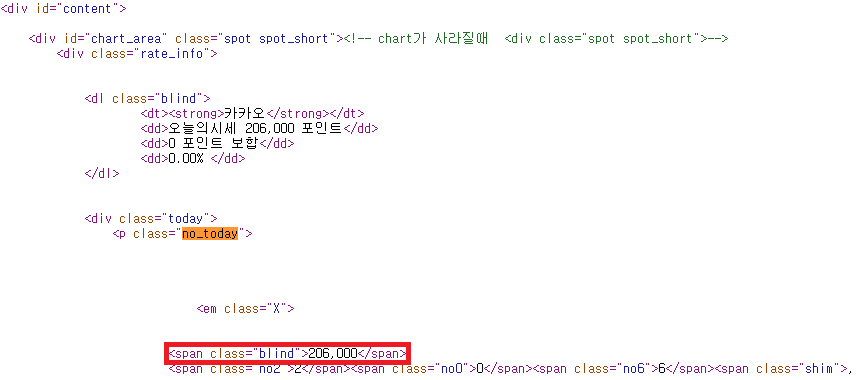
소스보기를 해서 보면 206,000 이라는 숫자가 있는 부분을 확인할 수 있습니다. R에서 명령어를 이용하여 저 부분의 값을 가져오면 당일 현재 기준 주식가격을 가져올 수 있겠네요.
1-2) 시간대별 시세
시간대별 시세는 페이지 구조를 가지고 있으니 먼저 각 페이지 번호에 컨트롤키를 누른 상태로 클릭을 하면 새로운 창이 뜹니다. 이때 어떤 주소가 나오는지 봅시다.

새로운 창(또는 탭)의 주소창을 보면 아래와 같습니다. 위의 개요 부분 주소와 약간 다른것을 알 수 있는데요 .
https://finance.naver.com/item/sise_time.nhn?code=035720&thistime=20200508161046&page=1
주소에서 붉게 표기한 부분 처럼 가변으로 적용할 수 있는 구조입니다. 해당 화면에서 오른쪽 마우스 클릭하여 검사로 html 구조를 봅시다. (크롬기준)
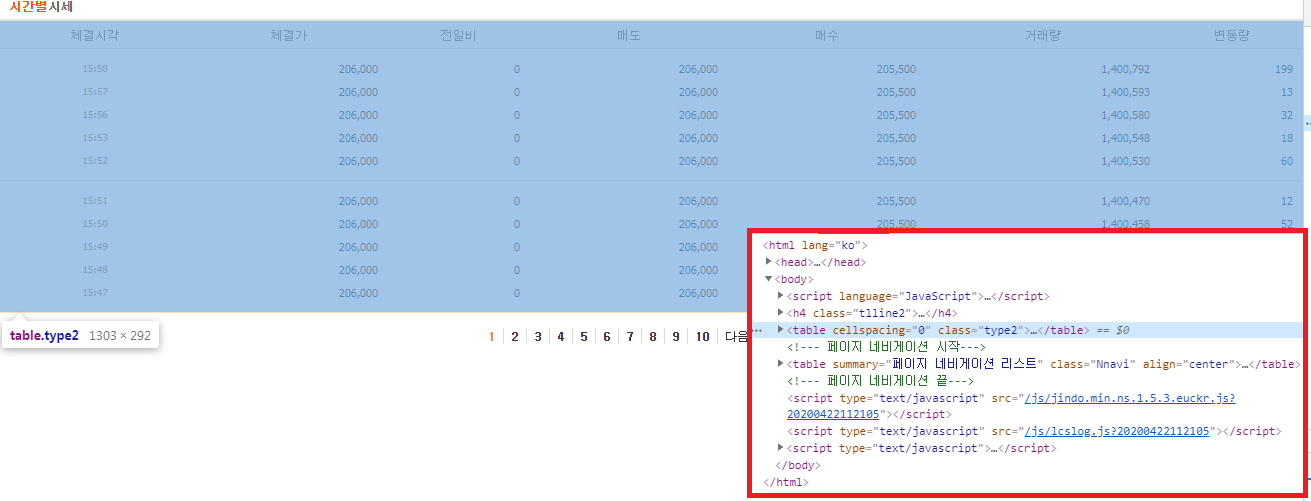
행복하게도 Table 구조를 가지고 있습니다. 이 경우는 가장 쉽게 데이터를 가져와 Data.frame 구조로 만들어 줄 수 있습니다.
1-3) 일자별 시세
일자별 시세도 1-2) 시간대별 시세와 동일한 방법으로 html 구조를 확인합시다. 먼저 url은 다음과 같습니다.
https://finance.naver.com/item/sise_day.nhn?code=035720&page=1
개발자 모드로 html구조를 확인해보면 아래와 같이 table 구조를 가지고 있네요.

2) 데이터 가져오기 (with R)
그럼 위에서 확인한대로 R을 통해 데이터를 가져와보겠습니다. 먼저 개요부분의 주식가를 가져와보죠.
library(rvest)
url <- 'https://finance.naver.com/item/main.nhn?code=035720'
htxt <- read_html(url, encoding='euc-kr')
위의 스크립트를 실행하면 htxt에 해당 페이지의 html 코드가 담깁니다. 이중에서 필요한 부분만 발라내어야 하는데 그 때 사용하는 것이 html_nodes() 함수 입니다. 이 함수를 활용하여 html 태그와 클래스명을 활용하여 필요한 부분을 추출해냅니다.
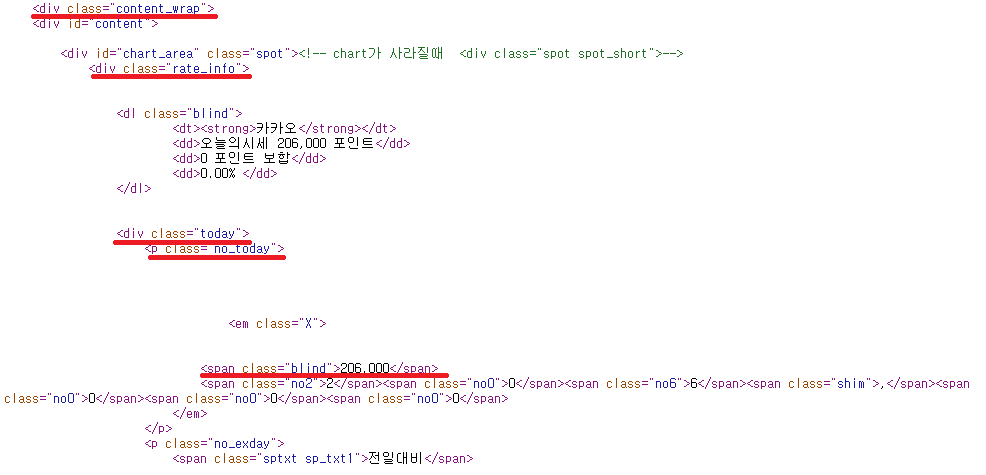
하단에 나와있는 206,000이라는 숫자를 빼내는게 목표입니다. 단계를 보면 아래와 같습니다.
div.content_wrap => div.rate_info => div.today => p.no_today => span.blind
이것을 스크립트로 구성하고 다음과 같습니다.
h <- html_nodes(htxt, 'div.content_wrap') %>% html_nodes('div.rate_info') %>% html_nodes('div.today')
price <- html_nodes(h, 'p.no_today') %>% html_nodes('span.blind') %>% html_text()
마지막에 html_text()를 이용하여 주식가격을 추출합니다.
library(rvest)
url <- 'https://finance.naver.com/item/main.nhn?code=035720'
htxt <- read_html(url, encoding='euc-kr')
h <- html_nodes(htxt, 'div.content_wrap') %>% html_nodes('div.rate_info') %>% html_nodes('div.today')
price <- html_nodes(h, 'p.no_today') %>% html_nodes('span.blind') %>% html_text()
price
다음으로는 일자별 시세를 가져와 봅시다. 앞서 말한 것처럼 Table 구조로 되어있을 경우 html_table() 함수를 활용합니다.
url <- 'https://finance.naver.com/item/sise_day.nhn?code=035720&page=1'
htxt <- read_html(url, encoding='euc-kr')
# html_table을 이용하여 table 내 데이터 가져오기
t <- html_nodes(htxt, 'table') %>% html_table(header = T)
# 첫번째 요소만 데이터가 있으므로
t <- t[[1]]
# 값이 없는 행 제거
t <- t[!apply(t=="",1,all),]
t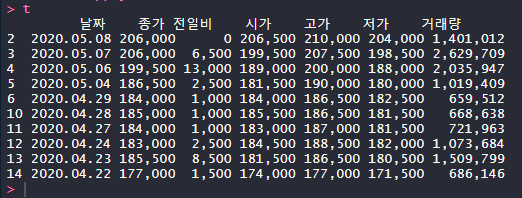
'Data Analysis > R' 카테고리의 다른 글
| [R] 주식 DATA 수집/분석 - 3 (0) | 2020.05.27 |
|---|---|
| [R] 주식 DATA 수집/분석 - NAVER 주식 Data 가져오기 -2 (0) | 2020.05.17 |
| [R] Apply 함수를 알아보자 (0) | 2020.04.21 |
| [R] DAUM 영화 평점을 가져와서 분석하기 - 2 (0) | 2016.02.23 |
| [R] Daum 영화 평점을 가져와서 분석하기 - 1 (2) | 2016.02.23 |




댓글