5-1. Data Relationship
Spotfire에서 가장 쉽게 사용할 수 있는 통계 기능은 Data Relationship 입니다. 말 그대로 데이터 내에서 관계가 있는 것들을 찾기 위한 기능인데 여기에 제공하는 Algorithm은 총 5가지입니다.
- Linear Regression (numerical vs numerical)
- Spearman R (numerical vs numerical)
- Anova (numerical vs categorical)
- Kruskal-Wallis (numerical vs categorical)
- Chi-squre (categorical vs categorical)
Linear Regression과 Spearman R, Anova와 Kruskal-Wallis는 대상이 동일합니다. 수치형 Column들간의 관계 또는 수치형과 명목형 Column들간의 관계를 분석하기 위한 것인데 차이점은 Linear Regression과 Anova는 Parametric Statistics(모수 통계) 이고 Nonparametric Statistics(비모수 통계)입니다. 각 용어는 통계의 학문을 크게 나누는 기준점으로 모수에 대한 가정을 하느냐 하지 않느냐로 나뉩니다. 일반적으로 잘 알려져있는 대부분의 통계분석 방법은 Parametric Statistics입니다. Spotfire는 통계를 잘 모르는 사용자들을 위해 제공하는 기능이기 때문에 복잡한 사전지식이 없이도 구동할 수 있게 설계되어있으며 가정에 대한 검증은 모두 제공하지 않습니다.
본 장에서는 Linear Regression, Anova, Chi-square에 대해서만 설명을 진행하겠습니다. Data는 Spotfire 설치 폴더에 포함되어있는 Example 파일 중 하나인 Baseball 데이터를 활용했습니다.

5-1-1 Linear Regression
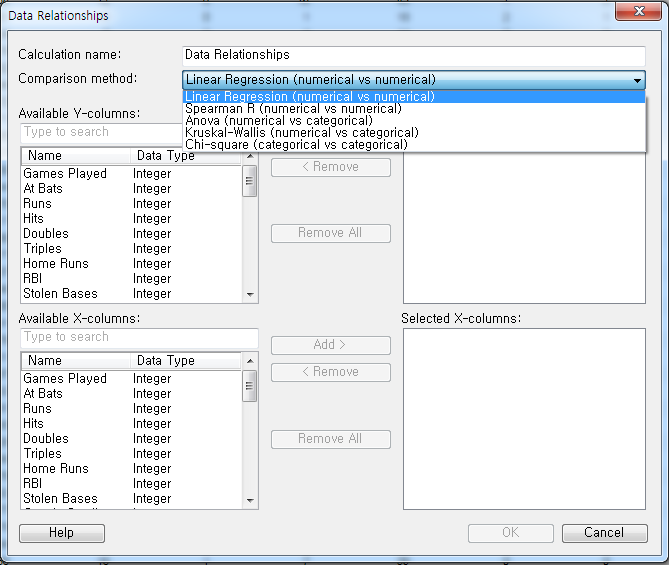
실행하면 먼저 Calculation name에 실행하는 분석에 대한 명칭을 부여할 수 있습니다. Comparison method에서는 위에서 언급한 5가지 Algorithm을 선택할 수 있습니다. 그리고 Available Y-columns와 Available X-columns에서 분석할 대상을 지정할 수 있습니다.
먼저 Linear Regression을 실행해보겠습니다.
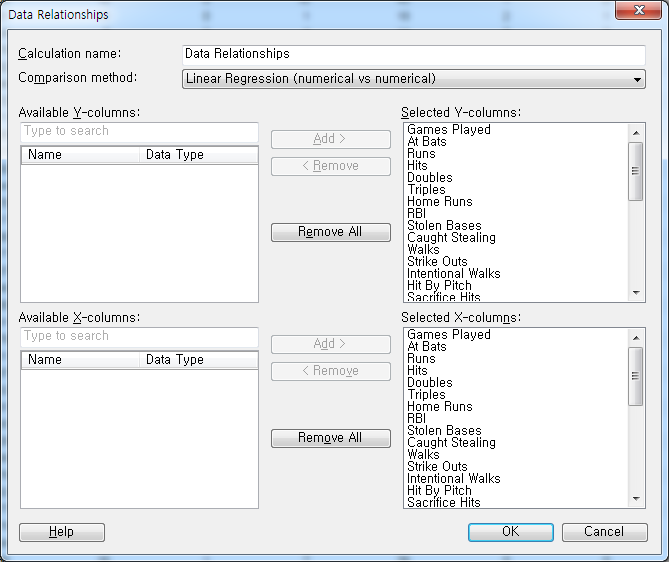
예전에 강의를 할때에 Data Relationship관련해서 잘모르면 그냥 모든 변수를 집어 넣으라고 이야기를 합니다. 통계를 아는 분이라면 어느정도 Column을 선별해서 선택하라고 이야기는 합니다만 그렇지 않은 경우는 모든 가능한 변수를 설정하라고 이야기합니다. 일단 모든 변수들을 각 X, Y에 모두 할당을 하고 OK를 누릅니다.

그냥 모든 변수를 넣고 돌리라고 하는 이유가 결과창을 보면 알 수 있습니다. Linear Regression을 실행하면 위에서 보는바와 같이 설정한 모든 변수에 대해 모든 조합을 출력하고 각 조합에 대해 Linear Regression을 수행한 후 그 결과를 테이블로 출력합니다. 각 테이블의 한 행이 하나의 조합을 의미하며 이를 Marking하면 하단의 산점도에서 해당 Linear Regression과 데이터를 보여주며 얼마나 잘 적합이 되는지를 확인할 수 있습니다.
앞서 말한 각 조합을 출력하는 테이블에서는 R-square 값과 p-value 값을 기준으로 이미 정렬이 되어있습니다. 즉 가장 위에 오는 조합이 가장 서로 연관성이 높은 조합이라고 볼 수 있습니다. 제일 상단에 있는 "At Bat"과 "Plate Apearance"가 가장 연관성이 높습니다. 여기서 p-value를 보려는데 보시는 것처럼 이상하게 뜨는 경우에는 Format을 지정해주면 제대로 볼 수 있습니다.
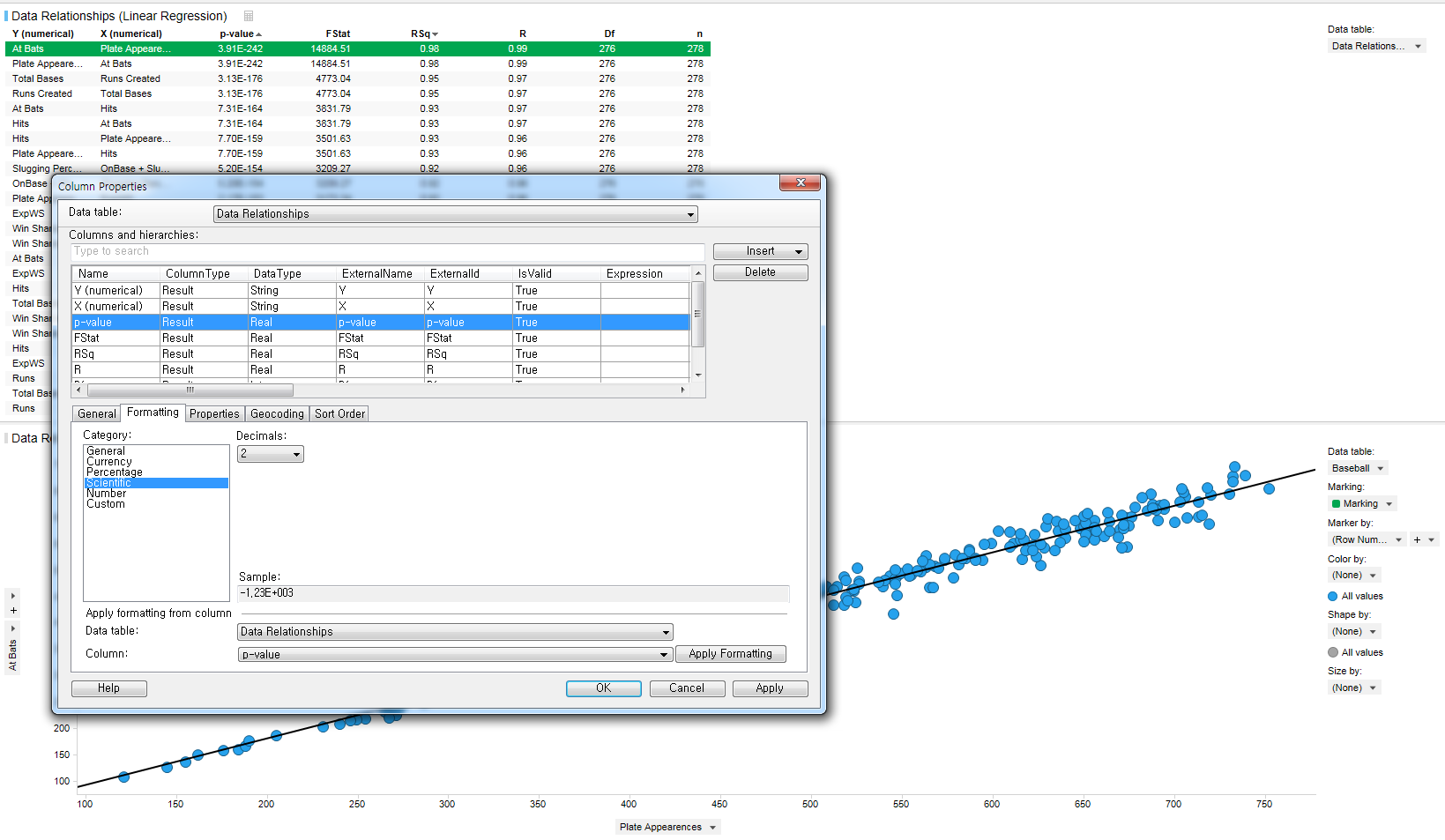
edit-column properties에 들어가서 p-value의 Format이 Scientific으로 되어있는데 이것을 Number로 변경합니다.

그러면 아래와 같이 P-value가 0.0000으로 소숫점 4자리까지 표현되는 것을 알 수 있습니다.

간단하게 해석하는 방법을 이야기 하겠습니다. 통계이론으로 들어가면 복잡해질 수 있으니 다음에 기회가 되면 보완하도록하겠습니다. 일반적으로 통계분석을 할 때 p-value는 0.05로 설정을 합니다. 이는 기준점이 되며 모형에 대한 유의성 검정의 결과가 0.000이며 0.05보다 낮으므로 이 모형은 통계적으로 유의미하다라고 합니다. 통계적으로 유의미하다고 해서 이 모형이 좋은 모형이라고 판단할 수는 없습니다. 다음으로 확인해야할 값은 R-squred Value 입니다. 이 값은 해당 모형이 주어진 데이터를 얼마나 잘 설명하고 있는지 달리 말하면 해당 모형이 데이터에 얼마나 잘 적합하여 의미를 가지는지에 대한 수치라고 볼 수 있습니다. 제일 첫번째 조합의 "At bat"과 "Plate Apearance"의 경우 P-value는 0.000, R-squared Value는 0.98로 매우 우수하다고 볼 수 있습니다. 실제 하단의 나온 산점도를 봐도 대부분의 데이터들이 적합선 위에 잘 놓여진 것을 확인 할 수 있습니다.

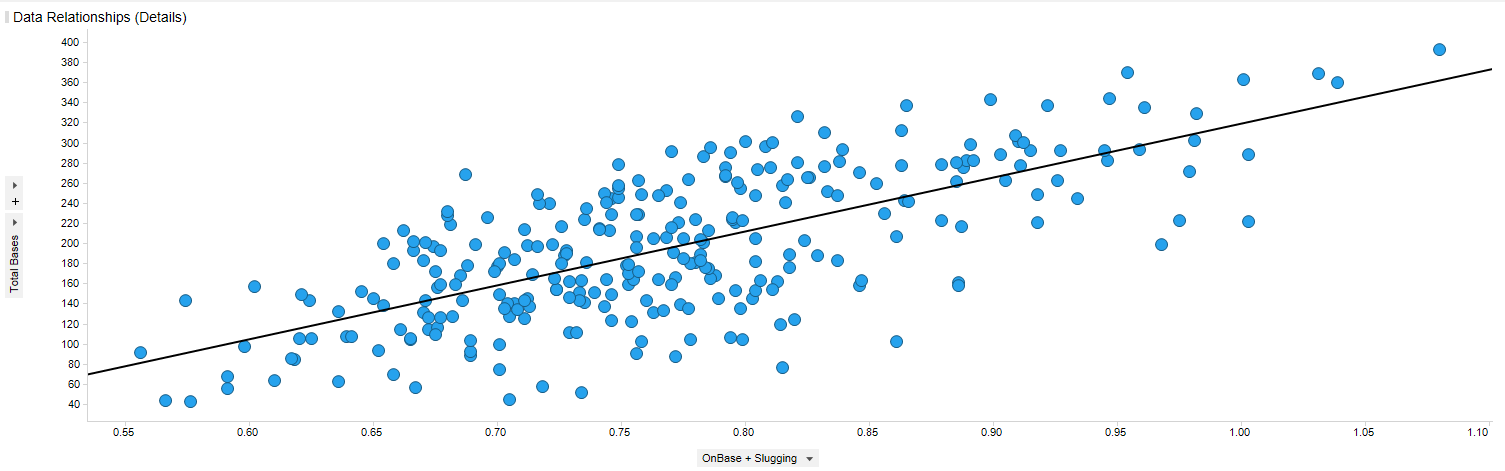
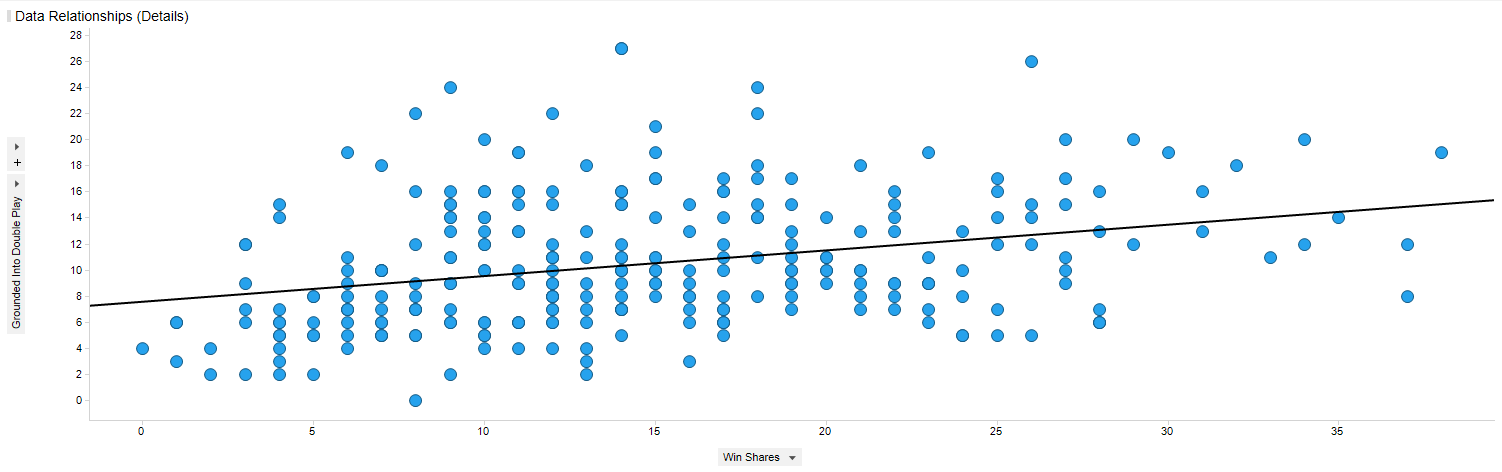
위에 나온 예제는 P-value가 0.000으로 통계적으로 유의미하지만 R-squared Value가 낮은 경우입니다. R-squred Value가 0.1입니다. 산점도를 보면 선을 중심으로 매우 넓게 퍼져 있는 것을 볼 수 있습니다. 이 경우 해당 모형을 쓰면 안됩니다. 명색이 교수라면서 R-squred Value가 0.1인 모형으로 논문을 쓰고 책을 쓰는 작자가 있더라구요.(한심)
R-Squared Value에 따른 모형이 어떻게 되는지 아래 이미지를 보면 대략 확인이 가능할 것 같습니다.




'Data Analysis > Spotfire' 카테고리의 다른 글
| [TIBCO Spotfire] Data Relationship - Chi-square (0) | 2019.09.25 |
|---|---|
| [TIBCO Spotfire] Data Relationship - Anova (0) | 2019.09.10 |
| [TIBCO Spotifre] Statistic Analytics (0) | 2019.08.30 |
| [TIBCO Spotfire] Information Link 활용법 - Fake element (0) | 2019.08.26 |
| [TIBCO Spotfire] Information Link 활용법 (4) | 2019.08.22 |




댓글