
안녕하세요 불탄오징어입니다.
Python 공부도 할 겸 틈틈히 통계 분석 모형들을 하나씩 수행해보려고 합니다. Python이 대세라서 한다기보다는 순수한 재미로 해볼려고 합니다. 현재는 업무에 Python을 활용하는 경우가 거의 없기도 하구요. 새로운 언어를 배우는 건 매우 재미있는 일이기도 해서요. 처음으로 다중 회귀분석을 정리해보려는데 사실 이미 Python으로 다중 회귀 분석을 수행하는 예제는 올린 적이 있습니다만 너무 정리 되지 않은 형태여서....
고치자니 귀찮고 새로 만들어진 마크다운 형식으로 써보고 싶어서 새로 정리해 봅니다.
여기서 굳이 통계적 이론부분은 다루지 않으려고 합니다. 워낙 오래됐지만 유명한 통계모형이고 쉽게 수행할 수 있는 모형이다 보디 웹상에 이미 많은 정보들이 공유되고 있어서요. 그리고 목적 자체는 제 개인 공부를 위한 것이니만큼 Python을 다루는데 집중하려고 합니다.
Regression
회귀분석은 연속형 변수 간의 관계를 설명할 수 있는 모형을 추정하는 통계분석 방법으로 가장 많이 사용되는 모형은 선형회귀분석(Linear Regression)과 로지스틱회귀분석(Logistic Regression) 등이 있습니다. 많이 사용 되는 통계 분석인 만큼 대부분의 통계분석 툴에서도 쉽게 사용할 수 있으며 그 외 여러가지 프로그램(엑셀)에서도 쉽게 지원하고 있습니다. 단 그에 반해 이론적으로 가정에 대해 검증해야할 부분은 약하게 다루어짐으로 오용되고 있지 않은가 라는 의견도 많은데요. 검증 절차에 대해서는 많이 다루지 않으며 통계학 전공자라고 하더라도 무시 또는 생략하는 경우가 워낙 많아서 결국 분석자의 역량과 판단에 달린 문제라고 보여집니다.
Linear Regression
선형 회귀분석은 독립변수, 종속변수가 각각 하나인 단순회귀분석( $ y = \beta_0 + \beta_1 x $ ) 과 2개이상의 독립변수와 하나의 종속변수에 대한 관계를 다루는 다중회귀분석( $y = \beta_0 + \beta_1 x_1 + ... + \beta_n x_n$ )이 있습니다. 주어진 데이터를 바탕으로 각 독립변수에 대한 계수값을 추정하는데 익히 알려진데로 최소제곱법과 최대우도추정법을 사용합니다.
Example
Python에 내장된 데이터셋으로 분석을 진행해보겠습니다.
Data 가져오기
# 데이터분석할거니까 pandas는 기본
import pandas as pd
# boston housing data
from sklearn.datasets import load_boston
boston_ds = load_boston()
그럼 boston_ds에 뭐가 있는지 봅시다.
print(boston_ds)

(중략)

하단의 Description이 알아보기 힘들게 나오네요.
일단 데이터(data)가 있고 target이 있으며 마지막에는 각 변수들에 대한 설명이 있습니다. 이 상태로 분석이 어려우니 pandas의 DataFrame() 함수를 이용하여 일반적으로 우리가 알고 있는 형태, Table, DataFrame 형태로 변경합니다.
boston = pd.DataFrame(boston_ds.data, columns=boston_ds.feature_names)
boston['target'] = boston_ds.target
boston.head()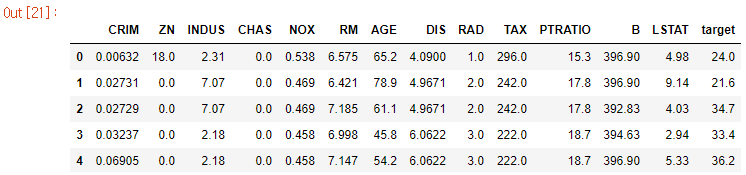
데이터 설명
| CRIM | Per capita crime rate by town (마을별 인당 범죄율) |
| ZN | Proportion of residential land zoned for lots over 25,000 sq. ft (25,000 평방 피트 이상의 거주지역 비율) |
| INDUS | Proportion of non-retail business acres per town (도시당 비상업 지역 비율) |
| CHAS | Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) (찰스강에 대한 더미 변수, 1 이면 강의 인근에 위치, 아니면 0, ※외국도 강변이 가격이 높나요? ㅋ) |
| NOX | Nitric oxide concentration (parts per 10 million) (질소 산화물 농도(10 ppm 당), 단어 어렵네요.) |
| RM | Average number of rooms per dwelling (주택당 평균 방의 수) |
| AGE | Proportion of owner-occupied units built prior to 1940 ( 1940년 이전 건설된 주택 비율 ) |
| DIS | Weighted distances to five Boston employment centers ( 5개 보스턴 고용센터까지의 가중 평균 거리 ) |
| RAD | Index of accessibility to radial highways (방사형 고속도로 접근성 지수) |
| TAX | Full-value property tax rate per $10,000 (10,000달러 당 부가가치세) |
| PTRATIO | Pupil-teacher ratio by town (마을별 학생, 교사 비율) |
| B | 1000(Bk — 0.63)², where Bk is the proportion of [people of African American descent] by town (마을별 아프리카계 미국인 비율, 왠지 기분나쁜 지수네요.) |
| LSTAT | Percentage of lower status of the population (모집단의 하위계층의 비율,.... 뭐야 이거) |
| MEDV | Median value of owner-occupied homes in $1000s (소유자 거주 주택 가격의 중간값) |
주어진 데이터는 위와 같습니다. 이 중 MEDV가 Target 이네요. 즉 주택가격을 종속변수로 놓고 어떤 독립변수를 조합하는 것이 가장 유의미한 모형을 만들 수 있으며 어떤 독립변수가 가장 큰 영향을 가지는지가 알고 싶은 포인트가 되겠습니다.
그럼 다음으로 회귀분석을 수행하기 위한 Python Package들을 불러옵니다.
회귀분석 수행
import statsmodels.formula.api as sm
from statsmodels.sandbox.regression.predstd import wls\_prediction\_std
그 다음 회귀식을 만들어서 분석을 수행할 건데 모든 변수를 넣고 회귀분석을 수행해보겠습니다. 수행한 결과에 따라 변수들의 유의성과 모형의 유의성, 설명력등을 보고 변수들의 조절하여 최종적으로 모형을 완성해갑니다. 먼저 다음과 같이 모든 변수를 넣고 모형식을 구성하여 회귀분석을 수행합니다. Python에서 아쉬운 점은 R의 경우 Formula 를 만들 때 종속변수를 제외한 나머지 변수를 모두 넣고자하면 "."을 활용하여 간단하게 구성이 가능합니다
target ~ .
# R에서는 위와 아래 코드가 동일한 Formula를 만드는 명령이다.
target ~ CRIM + ZN + CHAS + NOX + RM + AGE + DIS + RAD + TAX + PTRATIO + B + LSTAT
일단 Python에서 회귀분석을 수행하고자 하니 다음과같이 Formula를 작성하여 수행합니다.
result = sm.ols(formula = 'target ~ CRIM + ZN + CHAS + NOX + RM + AGE + DIS + RAD + TAX + PTRATIO + B + LSTAT', data = boston).fit()
result.summary()
그러면 결과가 다음과 같이 출력됩니다.

결과를 해설할 때 봐야할 부분을 표기했습니다.
- R-squred, Adj.R-squred : 보통 설명력이라고 말하는 값인데 주어진 데이터를 현재 모형이 얼마나 잘 설명하고 있는지를 나타내는 지수입니다. 단 R-squared는 독립변수가 추가될 수 록 증가하는 값이라 Adj.R-squared 값을 더 많이 봅니다. 업이나 분석자에 따라서 판단하는 기준이 다른데 교육교재나 도서에서나 0.9이상의 값을 볼 수 있고 현실적으로는 0.7 이상인 경우 설명력이 높다고 봅니다. 걔중에는 0.6까지 기준을 낮추는 경우가 있는데 ... 분석자의 판단이겠죠.
- Prob(F-statistics) : 모형에 대한 p-value 로 통상 0.05이하인 경우 통계적으로 유의하다고 판단합니다.
- P>[t] : 각 독립변수의 계수에 대한 p-value로 해당 독립변수가 유의미한지 판단합니다.
Adj.R-squared는 0.734, 모형의 P-value는 0.05이하로 통계적으로 유의미합니다만 AGE 변수에 대한 P-value가 0.954로 유의미하지 않습니다. 즉 AGE 변수는 Target에 영향을 주는 변수라고 볼 수 없습니다. 이 경우 AGE 변수를 제외하고 다시 회귀분석을 수행합니다.
result = sm.ols(formula = 'target ~ CRIM + ZN + CHAS + NOX + RM + DIS + RAD + TAX + PTRATIO + B + LSTAT', data = boston).fit()
result.summary()
그러면 결과가 다음과 같이 출력됩니다.

Adj.R-squared는 0.735로 더 좋아졌네요. 모형의 P-value는 0.05이하이고 모든 변수가 P-value 0.05 이하로 유의미한 결과를 보여줍니다. 변수들 중 질소산화물농도(NOX)가 1 증가할 때 주택가격의 값이 17이 감소하고 RM은 3.7, CHAS는 2.7 정도 집값 상승에 영향을 주네요. 질소산화물농도를 사람들이 측정하나보네요... 아니면 본능적으로 아는건가... 이래서 단순히 분석만 알아서는 안되는 것 같습니다. 데이터에 대한 이해와 배경에 대한 지식이 있어야 모형을 바탕으로 정확한 의사결정을 내리겠죠.
추가 고려 사항
처음 언급했던 것 처럼 회귀분석을 진행함에 있어서 확인하고 넘어가야할 부분들이 총 4가지가 있습니다.
- 정규성 : 잔차의 분포가 정규분포를 따르는지
- 등분산성 : 잔차의 분포가 등분산성, 즉 고르게 분포하는지
- 선형성 : 종속변수와 독립변수가 선형적 관계를 가지는지
각각 검증 방법/절차가 존재하며 경우에 따라 이를 해결할 수 있는 방법 또한 존재합니다. 하지만 대부분의 분석자들은 이부분은 생략하거나 모르거나 무시하고 있는 경우가 많습니다. 아무래도 빠른결과를 봐야하는 입장에서는 조금이라도 분석과정을 줄이고 싶은 마임으 있을 테니까요. 몰랐다면 어쩔 수 없지만 전공자이거나 알게된 이상 검증을 하는것을 추천드립니다.
다음 번에 기회되면 각 사항에 대해서 검증과 해결 방법에 대해서 다뤄보겠습니다. 추가로 R 같은 경우는 Stepwise, Forward, Backward 같은 변수 선택법을 함수로 지원하고 있는데 Python에서는 못찾겠네요. 따로 함수를 만들어야 하나봅니다.
'Data Analysis > Python' 카테고리의 다른 글
| [Python] 정규성 검정 (2) | 2020.01.27 |
|---|---|
| [Python] K-means Clustering (0) | 2020.01.23 |
| Python : Data Handling(수정) (0) | 2015.12.10 |
| [Python] jdbc로 Database(Oracle) 접근하기 (2) | 2015.12.03 |
| Python : 다중 회귀 분석 (0) | 2015.12.02 |


댓글