5-1-2. ANOVA
5-1-1. Linear Regression에서 처럼 Data Relationship에서 두번째 Comparison method는 Anova 입니다. Linear Regression이 numerical value 들 간의 연관성을 알아 보는 것이었다면 Anova는 numerical value와 categorical value 간의 연관성을 알아 보는 분석 방법입니다. 정확히는 통계 분석 방법인 ANOVA는 일원배치분산분석으로 각 집단간의 차이를 확인하기 위한 방법입니다. 두개 집단간의 차이를 확인하기 위해서는 t-test를 수행하는데 반해 Anova는 3개이상의 집단에 대해서 평균을 비교합니다. 집단을 구분한 값이 Categorical value로 지정되며 각 수치에 대해서는 numerical value로 지정합니다. 그럼 Sample Data를 활용하여 간단하게 분석을 진행해보겠습니다.
Sample Data는 잘알려진 Iris 데이터 입니다. 해당 데이터를 Spotfire로 가져옵니다.
iris 데이터는 잘알려져 있는 데이터 이며 앞서 설명한 바가 있으니 생략하겠습니다. iris 데이터에선 4개의 수치형 칼럼과 명목형 칼럼을 가지고 있습니다. 명목형 칼럼인 Species는 setosa, versicolor, virginica등 3개의 종을 나타냅니다. 각 종에 대한 4개 수치값의 평균 차이를 비교해보겠습니다.
Data Relationship을 실행하고 Comparison method에 anova를 설정합니다.
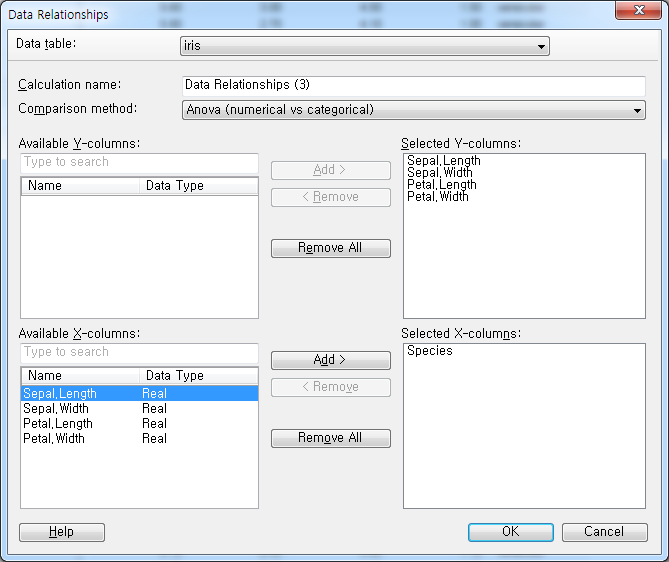
그 후 Y에는 4개의 수치형 값을 X에는 Species를 설정한 후 OK를 누릅니다.

Linear Regression과 동일하게 상단 Table에는 각 조합(X-Y)에 대한 리스트가 출력 되며 이번에는 p-value와 F stat값 기준으로 정렬이 됩니다. 그리고 하단에는 상단 Table에서 선택한 하나의 조합에 대해서 BOX plot이 출력됩니다. 실제 ANOVA 분석을 하게 되면 (1) 각 집단간의 차이를 비교하고 (2) 통계적으로 유의미한 의미를 가지는 집단간의 차이가 보이면 각 집단간의 세부적인 차이를 확인하기 위해 사후 분석을 진행합니다. 대부분의 통계분석 툴의 경우 사후분석을 기본 기능으로 제공하지만 Spotfire는 BoxPlot에서 제공하는 특정 기능을 활용하여 사후 분석을 제공합니다.
일단 p-value는 Linear regression때 처럼 소숫점 4자리로 변경하여 줍니다.
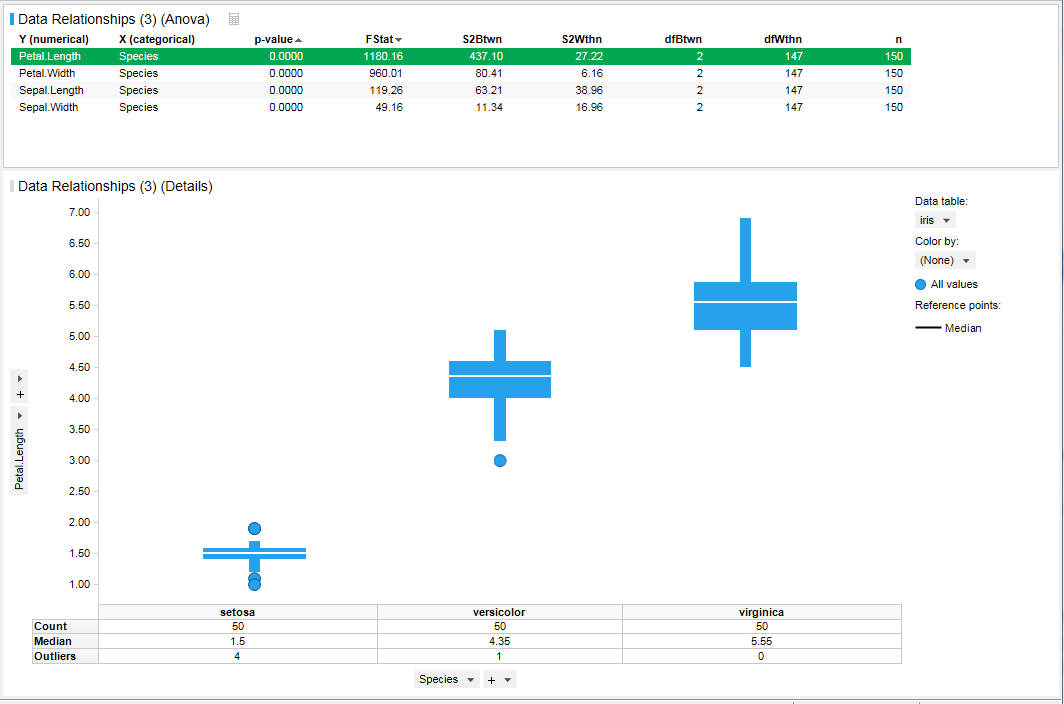
결과를 보면 모든 조합에 대해서 p-value는 0.05보다 낮기 때문에 각 집단별로 Petal.Length 부터 Sepal.Width 까지 모두 유의미한 차이를 가진다고 볼 수 있습니다. 그럼 각 집단의 차이를 비교할 텐데 Box Plot을 보면 setosa, versicolor, virginica 모두 눈에 보일정도로 차이가 있습니다. virginica가 Peltal.Length가 가장 길고 반대로 setosa가 가장 짧습니다. 이와 같은 경우 눈에 보일정도의 차이를 나타내지만 좀더 시각적으로 볼 수 있는 방법은 comparison circle을 활용하는 방법입니다.
Boxplot의 properties에서 Appearance로 가면 Show comparision circles 라는 옵션이 있습니다. 이를 체크 합니다.

그러면 아래와 같이 우측에 원이 나타납니다.
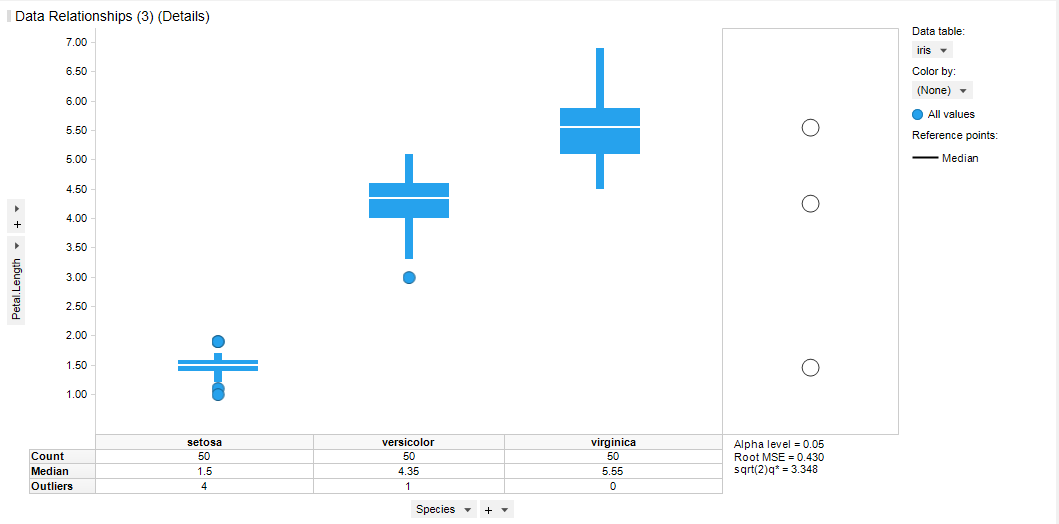
각 원의 중심은 각 집단의 중앙값을 나타내며 원의 크기는 산포를 나타냅니다. 원이 겹치면 두 집단 통계적으로 다르다고 볼 수 없으며 겹쳐지지 않고 떨어져있다면 두 집단은 통계적으로 다른 집단이라고 할 수 있습니다. 구체적인 계산식이나 방법에 대해서는 Spotfire의 Data Relationship 도움말에서 제공하고 있습니다.

Help에서의 설명을 말 그대로 설명을 위해 깔끔하게 구성 되어 있지만 애매하게 겹쳐져있는 것들은 확인이 쉽지가 않습니다. 통계를 잘 모르거나 수식에 거부감이 있는 경우는 Anova 결과에서 두 원이 겹쳐져있는지, 그렇지않은지를 기준으로 판별하시면 될 거 같습니다.
'Data Analysis > Spotfire' 카테고리의 다른 글
| K-means Clustering (0) | 2019.10.10 |
|---|---|
| [TIBCO Spotfire] Data Relationship - Chi-square (0) | 2019.09.25 |
| [TIBCO Spotfire] Data Relationship - Linear Regression (2) | 2019.09.04 |
| [TIBCO Spotifre] Statistic Analytics (0) | 2019.08.30 |
| [TIBCO Spotfire] Information Link 활용법 - Fake element (0) | 2019.08.26 |




댓글